Welcome to the blog. This is my first post, so before I get into it: I’ve wanted to write more consistently for a while I think mostly to force myself to articulate what I’m learning and the cleanest way to start felt like writing about something I just spent a semester on… Future posts will (hopefully) be a mix of engineering work-in-progress, notes on things I’m reading, and occasional opinions.
The setup Link to heading
For my grad-level NLP course at USC I spent the semester working on cross-platform prediction market equivalence detection on a team project with four classmates. The problem is not very exciting on the surface: Polymarket and Kalshi both list thousands of active markets, with significant overlap on major events. “Will BTC hit $100K by year end?” on Polymarket is the same contract as “Bitcoin ≥ $100,000 on 31 Dec 2025?” on Kalshi, but there’s no shared ID to tell you that. If you figure out which listings mean the same thing you can hedge between platforms when prices drift apart.
The first version we built was scoped to NBA markets only. The logic at the time: sports are tractable, titles follow templates, easy to annotate. We built retrieval, fine-tuned a small FLAN-T5, and measured F1 = 1.00 on the held-out set. A perfect (very overfit) classifier…
The first lie Link to heading
1.00 F1 scores are usually too good to be true. We assumed there was a labeling bug but the actual issue was more subtle.
The problem, which became obvious in retrospect, was how the candidates were generated. Our retrieval stage took each Kalshi NBA market and found its five closest Polymarket counterparts. Every candidate pair therefore already shared the same two teams and the same game date by construction. A model only needed to learn “these two market titles describe the same two teams” to get near-perfect accuracy (and a one-feature TF-IDF cosine gets you most of the way there). The classifier wasn’t detecting equivalence; it was rediscovering that our retriever was good at finding candidates that shared entities.
The F1 of 1.00 was just measuring the retrieval structure.
So we trashed the NBA setup and started over on the whole thing. I collected a December 2025 snapshot across all of Kalshi + all of Polymarket: 117,116 markets across ten domains (sports, crypto, politics, economics, tech, entertainment, science, world, legal, and a long-tail “other”). Retrieval went from ~2,500 candidate pairs to 473,505. None of the shortcuts that made NBA trivial existed anymore.
The silver labels Link to heading
Labeling 473,505 pairs by hand isn’t on the table in a semester, so we used an LLM as the annotator. I wrote a prompt that decomposed equivalence into five boolean sub-criteria — same event, same entities, same threshold, same direction, date compatible — plus a final match/partial/not_match label and a 1–5 confidence score. Qwen 2.5-14B ran under vLLM on a Colab A100 with JSON-schema-constrained decoding, labeling 60,000 stratified pairs in about 110 minutes at zero marginal cost beyond GPU time (thank you google for the student colab credits).
I felt good about the labels. Spot-checking against Claude Sonnet 4.5 (API call not my subscription) on the top-100 pairs showed 92% binary agreement. The five-boolean schema produced rationales that looked reasonable. We then trained three verifiers on the 60K silver labels: a logistic regression, an XGBoost over engineered features, and a fine-tuned FLAN-T5-base.
XGBoost got F1 = 1.00 again…
The second lie Link to heading
F1 = 1.00 means the same thing the second time.
What happened: the five booleans Qwen emits are tied to its final label by a mechanical rule. The prompt literally says “label match if all five are true, partial if some are, not_match otherwise.” I had included those five booleans as features in the XGBoost feature set. So the classifier’s “job” was to learn a conjunction over five binary inputs, which XGBoost does trivially. It wasn’t learning to detect equivalence. It was reconstructing the annotator’s decision rule.
This is a general problem with LLM-as-annotator pipelines, and I hadn’t seen it flagged in quite this form before but also probably didn’t do my homework well enough before setting this up. If the LLM emits both intermediate reasoning and a final label, and you train downstream models on the label while giving them access to the reasoning, you aren’t measuring a model. You’re measuring how faithfully the classifier can rediscover the annotator’s rule. That’s a different question, and it’s always easier.
The honest fix is to hold the intermediate features out of the downstream feature set. When I did, XGBoost F1 dropped from 1.00 to 0.54. That’s the real baseline. The fine-tuned FLAN-T5, which only ever saw the raw market titles, landed at F1 = 0.66 — up 22% relative on the honest baseline, which is also where I’d now expect a reasonable cross-domain pipeline to sit.
The ensemble Link to heading
XGBoost and FLAN-T5 made different kinds of mistakes. XGBoost was precision-leaner: when it fired, it was more often right, but it fired less often. FLAN-T5 was recall-leaner: it caught almost every true match but also produced a lot of false positives. Taking the intersection of the two (predict “match” only when both agree) traded 5 points of recall for 8 points of precision and landed at F1 = 0.70, which is the best number in the paper.
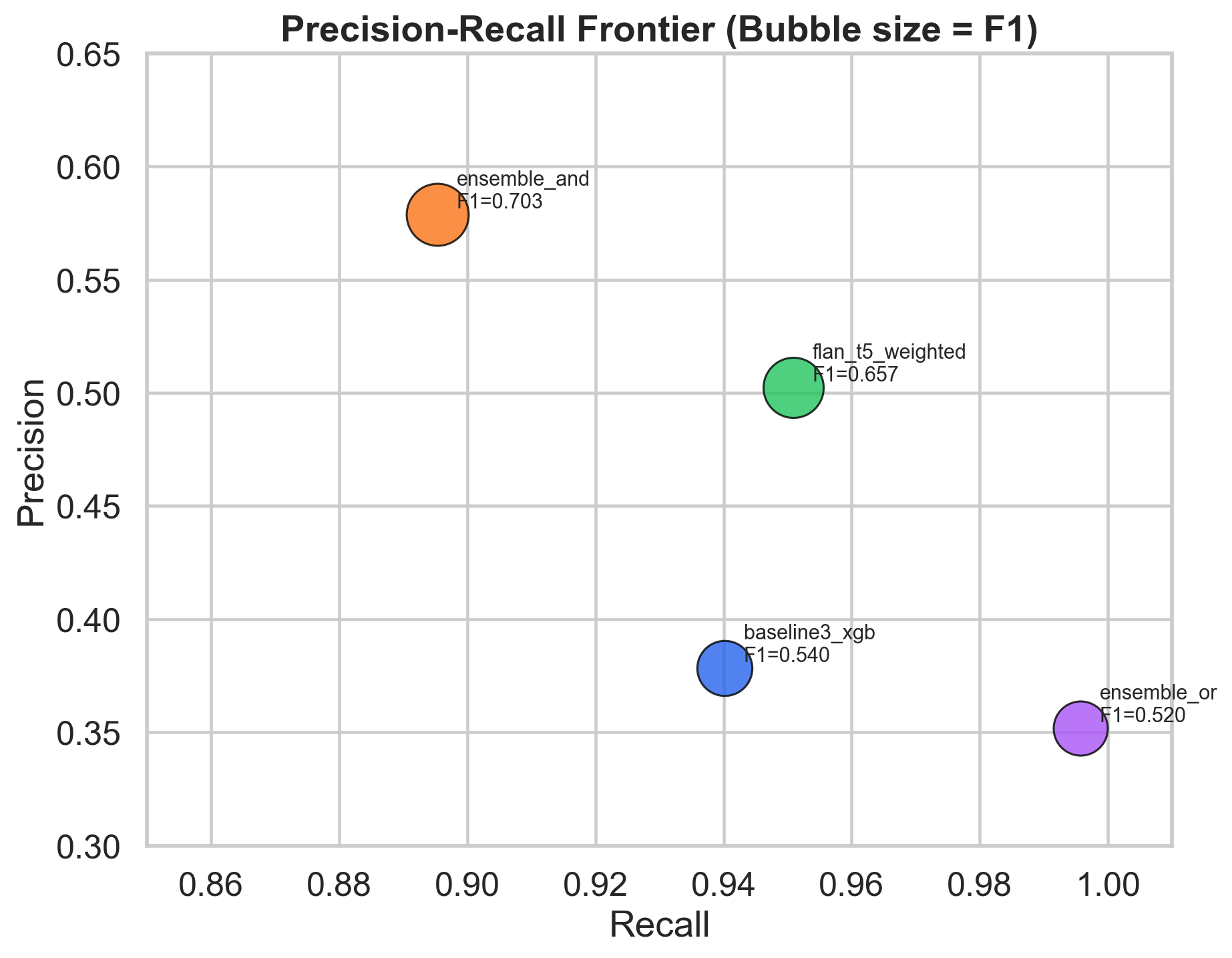
That one chart is the headline. The ensemble row sits above both components on the F1 isoline; the difference between XGBoost with and without the leaky features is about the same magnitude as the entire headline improvement.
What I’d do differently Link to heading
Three things.
Start with the hard version. We lost time building an NBA pipeline that turned out to measure nothing. I think the instinct to make it small and tractable first feels right in principle but wrong when the simplification removes the exact structure you’re trying to classify. If I’d started from cross-domain with a small sample and scaled up, I’d have hit the interesting problems earlier.
Audit the measurement before you run experiments. I should have done the leakage ablation the first week, not the last week. Any pipeline that uses LLM-generated labels should, before training anything, ask “what happens to my metric if I give my classifier the LLM’s full output, including the intermediate reasoning, and nothing else?” If the metric saturates, your downstream task is just reconstructing the annotator. If it doesn’t, you’ve shown your features contain signal independent of the annotator’s rule.
Pick your model to fight the prior, not complement it. FLAN-T5 is instruction-tuned meaning it has a strong prior about what “are these two things equivalent?” should return. When your positive rate is 4% and the prior says “usually no,” you need enough fine-tuning signal to move the model off that default. An earlier attempt on the smaller FLAN-T5 collapsed to always-no even after training; we had to switch to the base variant, bump the learning rate 3× over the default, oversample positives, and add a token-level loss weight before the model would actually learn. For binary classification on imbalanced data, an encoder-only cross-encoder (DeBERTa, etc.) is probably the better architecture than a seq2seq instruction model. We kept FLAN-T5 because the results came out fine; it’s still not the choice I’d make again.
Closing Link to heading
Code is on GitHub and the README has the full setup. The paper is in review for the course. I owe collaborators for most of the wins I claimed in this post: the retrieval infrastructure, the original annotation schema, and the evaluation pipeline were all someone else’s work.
Thanks for reading.